

As I’ve written time and time again, lying with statistics may not be the oldest profession, but it’s got to be pretty close. Alright, I may be exaggerating slightly. Modern propaganda and the P.R. machine got going around the time of the First World War, with many of the profession’s leading lights coming out of that time period — Edward Bernays, Walter Lippmann, Ivy Lee. But it’s a powerful tool of the propagandist today, especially the numerous prohibitionist groups and anti-alcohol organizations. So when I saw Think you drink a lot? This chart will tell you last month on the Washington Post’s Wonkblog, I noted it with suspicion and made a note to look at it closer when I had the time. What got my spidey senses tingling was the idea that “the top 10 percent of drinkers account for well over half of the alcohol consumed in any given year.” Here’s the chart the article ran, showing the data for that conclusion.
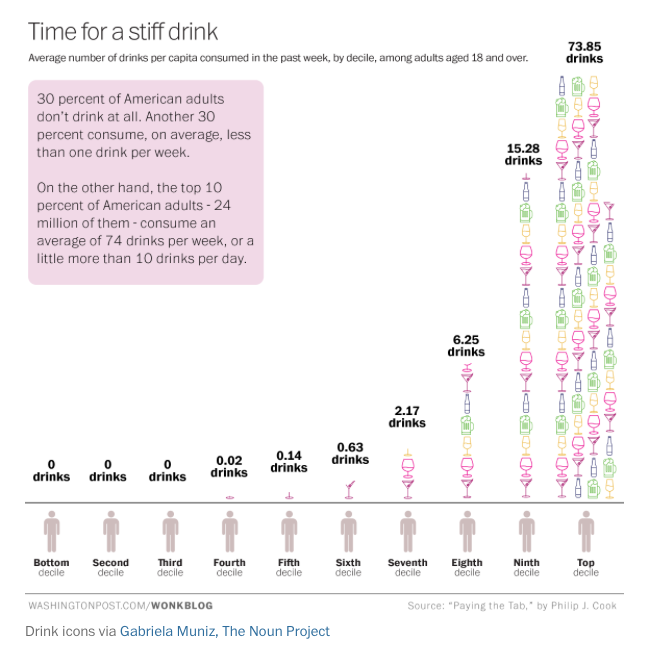
Although it shows the common Pareto Principle, it just didn’t ring true. That many people can’t, and don’t, drink that heavily. I knew there had to be another explanation for this data. And there is. Trevor Butterworth, writing for Forbes, did the heavy lifting on this one with his wonderful expose, When Data Journalism Goes Wrong. It turns out that when you drill down the data, looking at its source and analysis, things begin to unravel. Apparently the results of the original poll had the data manipulated by nearly doubling them to account for a perceived problem with under-reporting. To put that another way, the data was “fixed.” One of the problems with that (there are many, many, I’d say) is that people looking for data to support an agenda tend to seize on such manipulated data and pass it on, using it in their propaganda, and the mainstream media tends to fall for it uncritically, rarely looking at where the original information came from or how it was gathered. Happily, Butterworth does a good job of demonstrating where it all went wrong, and I urge you to read his entire When Data Journalism Goes Wrong. And a h/t to Maureen Ogle for sending me this. She knows me all too well.
There is nothing underhanded in fixing data per se, so it’s not enough to simply state “the data was fixed” and assume that bit of handwaving is enough to discredit the chart or its implications. You’d have to make an argument that the fix was inappropriate.
And the person behind the data reflected in the chart isn’t being at all sneaky with what his fix was (ergo, the Forbes writer did exactly zero “heavy lifting” on this aspect of his critique (although the rest of his piece has plenty)). The author relies rhetorically on the hidden agenda at Wonkblog, but here’s the author himself explaining what the fix was and why he used it…at the Washington Post (the mother of Wonkblog).
http://www.washingtonpost.com/blogs/wonkblog/wp/2014/10/03/measuring-americas-drinking-habit-is-tricky-heres-how-to-do-it/
I’ll admit I also have problems with the across-the-board 1.97 multiplier. It seems rather a blunt tool. The Forbes author doesn’t quite explicitly say what would happened to the distribution if Cook had been more precise. But it’s pretty standard practice in adjusting survey data to correct for under-reporting and not necessarily a propagandists weapon. It’s good data analysis practice.
So the question is, what would a different multiplier, or better, what would a series of multipliers do to the curve? Here, given time (and maybe also a paycheck) is how *I* would have gone about fixing this data.
We would definitely need more data to help us figure out what those new multipliers should be. We would want to know, for example, what individuals perceive to be an “appropriate” level of drinking. And we would want to know what the individuals perceive the actual drinking habits of the general population to be. (We could do this with individual data points or with population mean scores; the resulting correlations shouldn’t change much). We would want to know these things because an individual’s tendency to under-report and by how much would depend on where they actually fall on these two lines. Those who are near the perceived “appropriate” and “average” levels would not have as much incentive to under-report. They would provide one or more “truthfully reporting” data points.
Then we could make the assumption that anybody who reports that the “appropriate” and/or “average” drinking levels are greater than zero and also report drinking zero themselves are probably not “forgetting” what they’ve actually done. It isn’t hard to forget how many you’ve drunk, if you’ve not drunk any. We would want to use people who people the appropriate level is >0 because they think it’s OK to drink, but choose not to. People who believe the appropriate level is 0, have an incentive to claim 0 drinks, even if they’d had more. With less certainty we could use any individual who drinks less than the perceived “appropriate” level as being “truthful.” But we should have more confidence in the 0 reporters. This is our true “bottom decile.”
We would probably assume a curvalinear relationship (which more or less matches the Pareto curve) that runs between this “true 0” and also through the indexed point where all three “perceived appropriate,” “perceived average” “and “reported consumption” meet. This could be a single individual, but would hopefully be several “truthful” individuals at different points. This would capture the almost certain greater forgetfulness and motivated under-reporting of the uppermost percentiles.
This is a much more nuanced fix. But I predict you wouldn’t see much of a difference in the curve itself; certainly not in its shape (because of our curvilinear assumption) and most likely not in it’s magnitude. I think you’d see some more consumption in the 3rd (and maybe in the 2nd deciles) and slightly more in the 4th-9th deciles, but not much. And you may actually see an increase in the 10th…which would reflect greater drinks in the 96-100 percentiles and would drag upward the entire 10th decile.
I think the Forbes critique is decent, but incomplete and relies a little too much in attempting to read Cook’s mind and suss out his “intent.” The fact that he moves quickly from a genuine critique of Cook’s method to other people’s analyses of other data should be a warning that he doesn’t want to spend too much time on a substantive critique of Cook’s analysis.
Fixing data is not a problem. We need it to find signals amid the noise. Whether the fix is a good one or not is a different matter. The Forbes author does not even attempt to explain how his list of missed data would affect Cook’s chart. The Pareto curve in alcohol consumption (and it’s associated relationship to various tax policies) is a known distribution with or without Cook’s 1.97 multiplier. It’s a very common distribution in general and evidenced in NHANES and other surveys without any fix at all. The fact that he leaps so quickly from listing Cook’s methodological assumptions/defects to other topics without reanalyzing the data or even speculating on what his new data might imply about the curve, is indicative that he is (also?) the one with an agenda.
As always, I respect your writing and your careful reading of the prohibitionist agenda. We need more people critically engaging the public and teaching them how to read things like this. So I hope you take my comments here in the good faith in which I offer them.
Jim, no worries, I appreciate your adding to the discussion, and you make many good points. I didn’t really spend the time with this one I often do (mostly just because I’ve been busy with other work and traveling), but wanted to pass along the critique itself. I think you’re right that “fixing” isn’t the problem per se, but I do think it’s troubling that it’s often not disclosed or buried it footnotes that, let’s face it, many people don’t even look at.
A lot of that depends on the medium. In a book on the topic, burying it in the footnotes seems reasonable to me. You don’t want to bog down the prose with inelegant and wonky methodological processes. In a paper on the topic, you’d expect the methodology to be pretty explicit. Let me see if Cook published any papers in advance of the book. BRB
Agreed, in the book, yes it makes sense. But when it moved to another medium, Wonkblog, I believe it should have been incumbent upon the author there to bring it forward since in context I think it changes how one might view the data. As Butterworth points out in his critique, the raw data before being “fixed” is different, which we both think significant, but it’s not mentioned at all on Wonkblog, who instead says simply “These figures come from Philip J. Cook’s “Paying the Tab,” an economically-minded examination of the costs and benefits of alcohol control in the U.S. Specifically, they’re calculations made using the National Epidemiologic Survey on Alcohol and Related Conditions (NESARC) data.” He even claims to have reached out to Cook and “double-checked these figures” yet still never reveals that the raw numbers were changed by Cook. Yet his earlier statement about where the data came from is incomplete at best, and untrue at its worst, since the numbers were only based on the NESARC data and then altered from there. Without that information, I believe the story is inaccurate and paints a picture that’s not true, and certainly isn’t supported by the data since the data is based on undisclosed assumptions, which is why I used the titled misusing data, because it seems to me that’s what the Wonkblog did.
On a quick perusal of his name, nothing comes up specifically on this topic. He did write an article that seems to use the same figures used for the Chart in Question, but in that article, which is on a tangential issue, offers no citation at all and on methodology says very little.
Cook, P.J. and Moore, M.J. (2002). The Economics of Alcohol Abuse and Alcohol-Control Policies. Health Affairs. 21(2): 120-133.
Relevant bits on 121-122.
He does make clear that he is aware of the limitations of this data and he is upfront whence it came, but not what was done to it, if anything. What he says in this article doesn’t depend on the 1.97 multiplier. He mentions NSDUH but not any supply-side fix, so maybe he didn’t use it and therefore his citation was full as-is. He only says that “the top decile consumes over half the total alcohol” in order to discuss whether the Single Distribution Theory is necessary to support excise taxes.
On that, he’s definitely pro-tax. But it’s unclear if the research led him to be pro-tax or if being pro-tax led him to read and perform the research he has read and performed. (Being human, the answer is probably a little from Column A and a little from Column B).
Lately (the last 7 years at least) he’s written mostly on gun control. I’d search more but I have to earn my paycheck now. Cheers.
What’s being missed here is that YOU CANNOT QUANTIFY INTANGIBLES, which surveys have been trying to do forever & should give up trying. “Pigeon-holing” via multiple choice answers is total BS (especially when the q’s are tilted to reflect what the sponsor wants to hear – I’ll sell you a bridge if you think that no corp is putting up the $$).